
最新动态
新闻资讯
- 陈词滥调下的光影呓语——《异星战境
- 《GTA6》被爆再次跳票或延期至2026年发售
- OPPO Find X8 Ultra渲染图曝光:外观设计基本保持不变
- 精准控制!凌云光的FZMotion动捕系统助推人形机器人训练革命
联系我们
联系人:九游ninegame娱乐官网
手机:13833902999
电话:020-88920345
邮箱:sales@yjjfyw.com
地址:福田区沙头街道天安社区泰然四路3号天安数码时代大厦主楼1211
公司新闻
《现代电影技术》|陈军等:AIGC在电影虚拟摄制中的应用探索与实践
近年来,虚拟摄制技术在电影工业化、现代化制作体系中的发展与应用持续深化,其具有摄制工艺流程高度并行化、前期拍摄与后期制作深度融合化、视觉效果所见即所得等技术特点。数字资产的前期制作和现场重构是虚拟摄制技术的核心关键环节,对于加快虚拟摄制技术在数字视听行业推广应用具有直接和重要影响,其不仅要求前期制作的数字资产技术品质高,而且追求真实拍摄内容与重构数字资产的无缝虚实融合。当前,我国电影行业正在积极推进国家电影数字资产平台建设和全产业链智能化升级,伴随大语言模型和多模态模型的发展进步,人工智能生成内容(AIGC)技术愈加成熟,其具有高效优质、即时交互、发展迭代快等优势,可创新升级电影虚拟摄制技术流程,促进提质优化和降本增效,并有效克服虚拟摄制中数字资产制作难度大、成本高、资产利用率低、技术团队专业互性要求高等困难,因而非常适合服务电影数字资产制作。《AIGC在电影虚拟摄制中的应用探索与实践》一文以概念设计、场景生成、角色创建、动画生成、现场交互等为切入点,探索实践AIGC在电影虚拟摄制中的应用模式、技术适配与流程方案,对于推动AIGC技术服务电影虚拟摄制以及二者实现优势互补与融合并进具有重要的指导意义和应用价值。智能化是大势所趋,伴随算力、算法、模型、数据集、行业领域知识等不断发展完善,AIGC技术将不断逼近电影级技术品质,其在电影数字资产制作生产和电影虚拟摄制中的应用将日益成熟完善,进而有力支撑和服务国家电影数字资产平台建设与精品电影创作生产。
北京电影学院影视技术系研究员,主要研究方向:数字电影技术、电影虚拟摄制、电影智能制作。
北京电影学院影视技术系硕士研究生在读,主要研究方向:电影虚拟摄制、人工智能技术应用。
北京电影学院影视技术系副教授,主要研究方向:电影虚拟摄制、电影数字人、电影智能制作。
电影虚拟摄制凭借所见即所得的优势已在全球电影工业体系中得到广泛应用,但其后期前置的特点,导致前期高质量资产制作成本投入高,资产有效利用率较低,现场即时调整专业性要求高。人工智能生成内容(AIGC)技术以其高效生成和即时响应的能力可以有效弥补虚拟摄制的上述应用短板。本文通过AIGC技术在概念设计、场景九游娱乐平台生成、角色创建、动画生成、现场交互调整等各阶段的具体应用,探索人工智能(AI)如何在电影虚拟摄制各环节发挥效能,分析总结AI技术的优势、劣势及其与电影虚拟摄制的适配性,形成一套电影虚拟摄制的智能制作流程和实践方案。
电影虚拟摄制是电影行业最新的技术变革之一,其将前期拍摄与后期视效有机融合,降低了电影的制作成本,缩短了制作周期,丰富了创作手段,提升了画面视觉效果[1]。尽管电影虚拟摄制具备诸多优势,但仍面临技术复杂、对设备高度依赖以及高额成本投入等挑战[2,3]。如何通过创新的技术优化流程以降低成本成为当前研究的关键问题[4]。在此背景下,新兴的AIGC技术成为解决问题的首选。
当前,AI技术发展迅速,尤其是以ChatGPT和Sora为代表的AIGC技术,对诸多行业产生了深远影响。凭借其强大的学习力、生成力和创造力,AIGC技术已成为促进行业升级和迭代的关键驱动力。在电影制作领域,尤其是电影虚拟摄制中,AIGC技术展现出巨大应用潜力,帮助虚拟摄制快速创建数字资产、提升现场交互能力、降低操作复杂性,为解决虚拟摄制当前面临的挑战提供了新技术方案。
近年来,电影LED虚拟摄制在全球市场大放异彩,在国外,该技术已陆续被应用于《曼达洛人》第一至三季[5]、《黑客帝国:矩阵重启》、《星球大战:骨干小队》、《西部世界》第四季、《毒液:最后一舞》等大型影视制作中。2023年荣获多项国际奖项的《瞬息全宇宙》以及2024年奥斯卡获奖作品《可怜的东西》也采用了这一技术[6]。在国内,从热播电视剧《繁花》《云之羽》《大梦归离》到短剧《柒两人生》《太古至尊》,从京剧电影《安国夫人》、舞台剧《麦克白》到即将上映的剧情长片《流浪者号》,虚拟摄制技术也逐渐为行业所采用,成为影视制作的必要手段[7-9]。
然而,虚拟摄制技术推广应用的同时也暴露出一系列共性问题:创作者在前期构建数字资产,尤其是涉及高质量三维建模以及复杂视觉效果的制作时,常面临高昂的成本,前期投入压力巨大;拍摄现场的即时变更调整需要专业的技术团队;生产出的高精度数字资产有部分未采用,导致资源浪费[10,11]。这些问题让部分影视制作项目不得不重新权衡采用这一技术的利弊。显而易见,电影虚拟摄制技术未来要走得长远,必须要解决这些问题。
当前,AI在视听领域的应用取得了突破性进展,包括高清修复、无标记点动作捕捉、数字虚拟角色构建及智能建模和渲染等技术,均在推动电影制作流程向智能化演进升级。与此同时,各类智能影像生成工具不断涌现,尤其是Sora的出现,对影视行业产生了重大影响,诸多国内外电影作品已开始将AIGC技术应用于数字特效制作。
尽管AIGC技术具备生成速度快,易于使用等优势,但现阶段其生成的图像质量不高,无法直接用于电影画面。但由AIGC形成数字资产,作为电影虚拟摄制环节中的主体画面元素,仍具备广阔的发展与应用前景。
由于目前LED虚拟摄制现场的摩尔纹问题,摄影机镜头不会聚焦于LED背景墙上,因此对于三维实时渲染引擎渲染的数字资产精度要求有限;LED显示内容多为距离较远的背景,很多可以用二维场景替代高质量三维场景。此外,AIGC提供的自然语言等简易交互方式也解决了电影虚拟摄制现场交互技术专业性强的问题。因此,AIGC技术的引入成为均衡制作速度和制作精度的最佳方案,虽然AI生成的视觉内容在质量和精度上尚不能完全满足影视级画面的严格标准,但已能够在一定程度上满足LED虚拟摄制的基本需求(图1)。
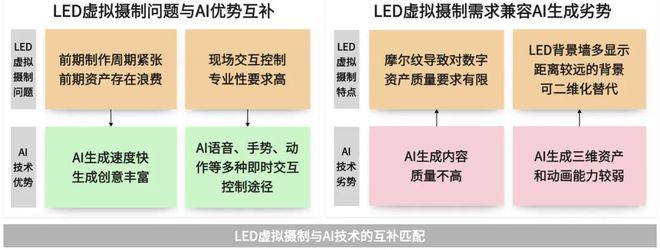
因此,融合以快速生成和即时响应为特征的AIGC技术[12,13],降低对高成本投入和设备的依赖,拓展创作自由度,不仅契合了电影虚拟摄制目前面临的技术局限,同时也完美弥补了后期前置导致的问题。此外,AIGC技术的引入为创意表达注入了新的可能性,赋予创作更大的想象空间和更小的执行成本。
针对LED电影虚拟摄制的相关难点,AIGC技术可以进行对应的多方位应用(图2),不仅提升了制作技术的前沿性,也在生产效能、内容创作、交互优化等关键维度弥补虚拟摄制现有的问题,为创意表现方式提供了更为广阔的空间。
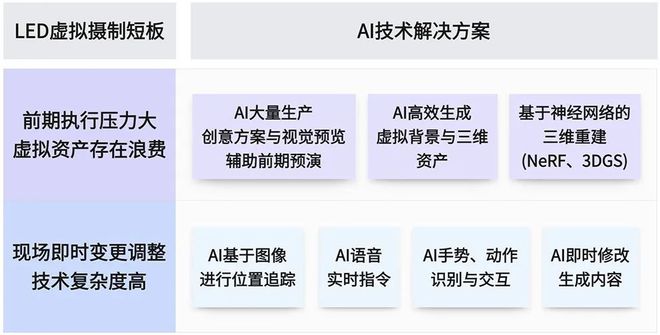
在前期内容生产环节,AI主要通过高效生成与即时预览的整合,实现生产流程的智能化升级。基于文生图技术,AI让2D景观被实时构建,并通过计算深度信息模拟3D动态视差,这对劳动密集型3D环境搭建团队而言,是一种快速且经济高效的替代方案。2023年上映的《雷霆沙赞!众神之怒》以及电视剧《海盗旗升起》等通过由AIGC生成的图像作为数字资产,通过2.5D方法,将AI生成的图像进行分层,为每张分层后的图像赋予深度信息,以便在摄影机追踪时为背景提供运动感。AI技术的引入,使这部电影的虚拟摄制流程得以实现更快的原型设计和迭代,制作团队能够更快速地试验和修改创意。此外,随着3D高斯溅射(3D Gaussian Splatting, 3DGS)、神经辐射场(Neural Radiance Fields, NeRF)等技术的出现,三维场景的重建和渲染只需使用一个视频或一组多视角照片。如梵蒂冈、微软和Iconem合作通过3DGS技术创建了圣彼得大教堂的数字孪生体,供观众以沉浸式的方式参观,基于多视角的高分辨率图像结合AI技术,3D版的圣彼得大教堂能够达到毫米级精度。AI技术的应用,在前期制作虚拟资产阶段显著降低了对计算机生成图像(CGI)团队的依赖。通过处理文本提示词、图像或视频,AI能快速生成数字环境内容,实现即时生成、即时使用的3D效果,消除了创造高质量三维资产的成本障碍。
在现场拍摄环节,结合图像编辑AIGC工具,如边缘抠像、智能填充、蒙版、笔刷等工具配合文本提示词,使AI能够在学习和理解场景的基础上,根据创作者的需求进行快速反应与调整,同时确保视觉内容的连贯性与质量的一致性,实现对资产内容的智能调整,增加了现场修改、场景交互的可行性。如Quantus开发的AI场景扩展流程通过智能拓展拍摄画面中的全景部分,显著降低拍摄对LED背景墙面积的需求和前景置景的成本。此外,随着当前多模态AI的爆发式增长,可使用语音指令、声音提示、手势动作、实时视频流等多种交互方式,使创作者可在不依赖硬件设备的情况下专注于拍摄细节。Verizon创新实验室结合AIGC和扩展现实(XR)技术,通过语音指令控制虚拟背景的生成和切换;CoPilot团队结合ChatGPT,通过对接Cesium开源地理空间平台和谷歌地图API,使用一句提示词即可在虚幻引擎(UE)内跳转至任何地理位置的三维地图场景。这种多模态人机交互方式将视觉、听觉和触觉结合,显著降低了技术要求,提升了操作效率,使创作者能更加流畅地完成复杂任务。
因此,充分利用AI减少工作量,同时最大化创意空间,能有效降低虚拟摄制的前期执行压力,扩大拍摄现场的实时修改空间,提升人机交互效果。
当前的LED虚拟摄制流程分为几个阶段。在前期筹备阶段,需完成剧本分镜创作、美术概念设计、制片计划制定等工作;在前期制作阶段,需完成虚拟预演工作,包括创建数字资产、搭建虚拟场景等工作;在现场制作阶段,主要完成制作环境配置和摄影机内视效拍摄任务,这一流程极大地减少了后期制作阶段中视效制作的工作量[14,15]。
由于LED虚拟摄制的技术复杂度高,制作过程需要一支专业技术团队提供服务[16]。技术团队需与创作团队保持密切沟通,在前期制作阶段,制作数字资产和完成数字场景工程等;在现场制作阶段,进行场景调整和环境匹配,随时解决突发技术问题。该过程的高耦合性和间接创作方式制约了LED虚拟摄制的应用推广。
AI技术的引入为复杂的虚拟摄制工作流程提供了一个崭新的维度,使创制流程得以重塑。在这一体系中,资源配置、AIGC以及实时交互作为核心组成部分(图3),相互间的协同作业顺畅、高效、便捷。主创人员可借助基于AIGC的全流程虚拟摄制平台,快速实现剧本分镜和概念设计,便捷调用和调整数字资产,实时与虚拟内容交互,这为电影创作提供了更为广阔的创意空间。
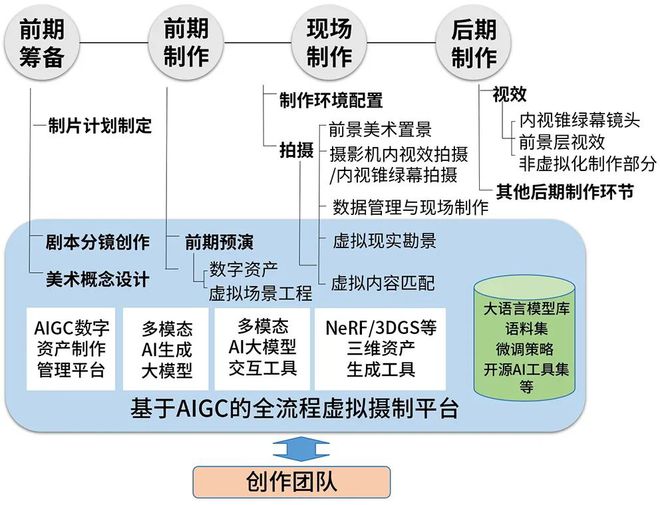
传统的电影虚拟摄制流程中,创意的产生与实现常常涉及多步操作,需要跨平台、跨设备地进行切换[17]。而AI技术为虚拟摄制提供了统一简易的操作平台,使所有创作工具和资源都能在同一环境中被调用,同时减少了虚拟摄制对实体硬件的依赖,降低了制作成本。
如Vū One将多样化的虚拟摄制套件整合为一体化的工具平台,包含了生成式AI、2D与3D资产库、SceneForge预演可视化工具、Remote VP远程控制等内置工具,以及与UE、Volinga、Frame.io、Shutterstock、Unsplash等平台的内部集成,构建了一个高度融合AIGC的简易高效虚拟摄制工作流程。通过接入外部自然语言大模型,Vū One将多模态AI大模型无缝融合至虚拟摄制的各个阶段,如生成平面图像发送至LED背景墙并立即显示;即时调用AI生成的丰富的数字环境资产库;通过深度信息计算,将2D平面图像转化为具有透视视差的3D模型,以匹配摄影机运动变化等。
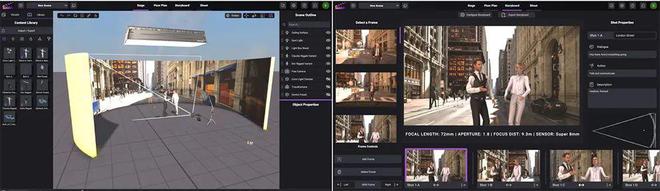
此外,结合三维实时引擎的灯光照明、地形编辑、时间轴动画、摄影机追踪等功能[18,19],配合接入AIGC生成的数字背景,可显示在虚拟LED背景墙上进行视觉预演(PreViz),以生成故事板和镜头列表(图4)。与生成式AI合作的工作流程将允许创作者在拍摄前大量试验视觉效果和拍摄手法,通过可视化的场景预览,创作团队可更直观地交流和讨论创作意图,顺利衔接到正式的拍摄中。
将多模态人机交互方式与AI、AIGC以及图像算法进行结合,能够大大降低LED虚拟摄制中交互控制的专业要求,虚拟资产可依据创作者的实时指令进行动态调整,确保创作者即时掌控视觉效果。如Cuebric将传统的图像编辑工具与AI生成功能结合,如画笔、橡皮擦、选区、蒙版、颜色编辑等,允许用户在虚拟画布上自由创作和修改细节,同时精准地选择特定区域进行编辑(如图5中通过笔刷绘制选定区域,结合新的文本提示词修改画面主体元素)。AI的引入极大增强了这些传统工具的功能,如通过深度学习算法智能识别选区,精准捕捉复杂的对象边缘,结合文本提示词同步生成内容等。此外,通过实时通信协议结合图像控制接口,能实现移动设备与控制系统间的低延迟通信。创作者能在移动设备上实时调整虚拟资产的显示比例、光照、颜色、视差深度等,无需复杂的硬件连接和专业的技术能力。

生成式AI模型与各类虚拟摄制套件结合,使复杂的虚拟摄制流程得以在精简的技术堆栈上运行,创作者无需大量的预算和技术经验也能具备实现创意和讲述故事的可能性。其高效的实时调整能力使拍摄过程中的即时修改和交互都较为灵活和流畅,极大提高了现场的人机协同效率。
虽然现阶段AIGC生成的内容存在质量不稳定,需要额外的人工干预和调整,生成的虚拟资产可容纳的摄影机运动范围也极为有限,与三维实时引擎的集成度较低,难以做到无缝实时交互的体验等问题,但已有的AI大模型能够结合虚拟摄制的场景流程得出不同的应用方案,通过开放式的人机协作流程,组合出合适的场景预设,将复杂且成本极高的虚拟摄制流程简化并嵌入易操作的系统中,让创作人员有更加友好的应用体验。这不失为虚拟摄制升级迭代的有效方法。
如今,电影虚拟摄制技术正不断完善,许多技术问题得以克服[20-22],但缺乏丰富且适用的数字资产问题始终未得到有效解决。高成本的传统三维资产制作方式极大提高了虚拟摄制成本,且存在部分完成的三维资产不被采用的浪费情况。AIGC技术的发展为数字资产的生成和使用提供了全新的方式。
2.5D图像通常由一系列带有透明背景的分层平面图像组成,2.75D图像则由具有多边形网格的分层深度图像组成(图6)。2.5D/2.75D图像能提供比2D图像更丰富的深度信息,但相较3D模型可大幅减少计算机的处理和计算。其核心在于获得相对目标场景或物体的深度信息,这通常通过深度传感器(如激光雷达或结构光相机)、立体视觉(通过两个摄像头模拟人眼视差)或单目深度估计算法(通过卷积神经网络从单一图像中推断深度)来实现。深度信息用深度图表示,提供每个像素到摄影机的距离数据,一旦获取深度信息,该信息可与传统的2D图像相结合,以生成2.5D或2.75D效果。相较于2.5D图像,2.75D图像能提供更多的深度信息,可容纳更大的视角变化,提供更真实的三维效果。

利用AI生成平面图像并将其转化为2.5D/2.75D深度图像(图7),可应用于电影虚拟摄制中。在2.5D/2.75D图像视差中,不同的图层会以不同的速度移动。通常距离摄影机更远的图层和物体移动得更慢,而近处的物体移动得更快,以此在摄影机移动时产生场景的深度感。AIGC可通过文本提示词快速生成图像内容并即时修改,并基于图像智能识别完成场景分层并赋予各图层深度信息,最终完成2.5D/2.75D场景的搭建。将深度图与平面图像结合,生成多视角可调整2.5D/2.75D图像。
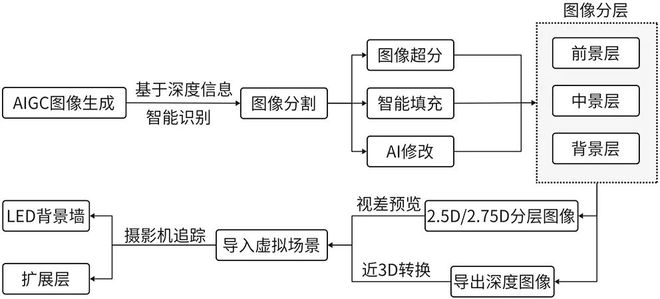
(1)生成图像:使用生成式AI从文本描述生成高分辨率的场景平面图像。通过正向提示词、负面提示词、生成模型、生成风格等对生成内容进行控制。使用局部蒙版结合文本提示词,进一步移除或修改图像中的局部区域或物体。
(2)图像分割:将生成的2D图像分解为多个图层,包括背景、中景、前景等。通过AI图像识别和深度估计算法,可实现以物体边界分割或通过计算深度值进行分割。
(3)分层输出:分层的图像为原始图片中割裂独立的各个部分,由 AI扩展分层图像的缺失部分,使每一层图像的内容都完整成立,以免在摄影机运动中产生撕裂(图8)。
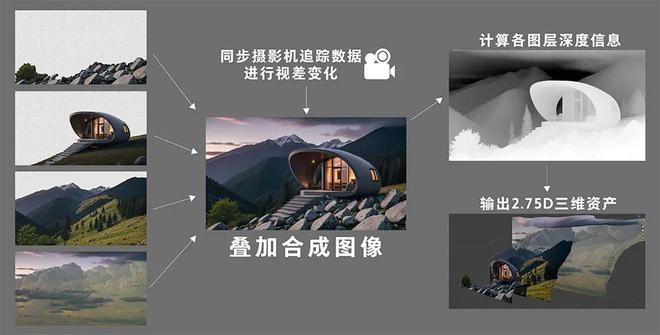
(4)深度信息整合:对生成的平面图像进行深度信息计算,或手动设置各图层的Z深度值。将深度图与平面图像结合,转化为多视角可调整的2.5D/2.75D图像,同步摄影机追踪数据后,即可作为虚拟场景应用于虚拟摄制。
AIGC生成2.5D/2.75D图像的虚拟场景搭建流程,以当前较为成熟且高效的文生图技术为核心,极大地降低了虚拟摄制中创建复杂场景等数字资产的工作量,使短期和中小型成本的虚拟摄制流程提速降本。
然而,2.5D/2.75D图像生成的主要挑战涉及深度数据的准确性和完整性,噪声、遮挡物处理和分辨率限制都需要优化。这套流程在实际创制过程中,最大的使用障碍在于图片生成的不可控性,在对分层的图片进行填充时,由于AI对物体边界理解的不准确,填充生成的画面容易出现伪影、模糊区域或不自然细节。当图像处理、蒙版情况变得复杂,以及在处理高分辨率和大规模数据时则会遇到性能瓶颈,使场景创建的过程卡顿和不流畅。此外,由2.5D/2.75D图像构成的数字环境,能支撑和满足的虚拟摄制应用场景较为有限,但其能快速执行微调、修复和深度分割,并将这些功能无缝集成到实时工作流程中,仍是极大降低LED背景环境创建成本、减轻创意执行压力的有效方案。
得益于大型预训练的文本到图像(Text⁃to⁃Image)模型在多视角图像生成中的应用,AI可基于扩散模型生成沉浸式场景,特别是全景图像,作为HDRI贴图应用于虚拟摄制中。传统全景图像的获取成本较高,而AIGC可通过文本或图像生成全景图(图9)。
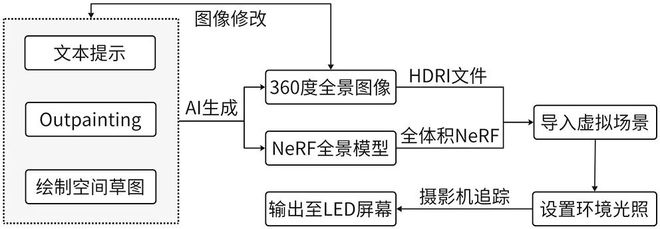
如SD⁃T2I⁃360PanoImage、PanoDiffusion等开源模型通过图像外扩(Outpainting)技术提供了一种将单视角图片扩展为全景图像的方法。ZeroNVS模型结合3D感知编码器和NeRF技术,能够从单张线度全景模型,Skybox AI推出了Sketch⁃a⁃Skybox功能,支持直接在球体、立方体等不同辅助网格下绘制立体空间草图,并结合文本提示词生成或进一步修改全景画面内容。
AI生成全景图像作为虚拟场景,相较于2.5D/2.75D方法,无需专业的图像编辑技能和软件后处理流程,即使是没有任何图像编辑经验的创作者也可轻松上手。此外,全景图的可扩展性较高,可导出应对多种需求的文件格式供后端工作流继续使用,与主流3D开发平台无缝集成。
全景图具备真实环境的光照和色彩信息,可容纳更大范围的摄影机移动,且在AIGC技术辅助下,图像的生成和处理都非常方便快捷。但相应地,要对其中的光照条件和物置、大小等具体细节进行修改和控制则相对困难。此外,全景图本质上仍是二维的平面图像,缺乏场景内的动态深度信息,而在摄影机运动过程中,观众对于空间深度的感受主要来自前景、中景和背景之间的视差变化,全景图无法提供这种动态的深度体验,仍需要结合具体需求和场景特点考虑是否使用全景图作为虚拟场景进行拍摄。
使用摄影测量法进行三维重建的场景可支持在虚拟环境中自由移动,但需前期大量的数据采集及专业技术人员的手动调整。NeRF提供了一种用于合成新视角图像的深度学习方法,可从多个已知视角的2D图像中学习并预测,以从任意视点渲染场景,生成具有高度细节的三维表示,呈现出具有准确透视和线)。与传统的摄影测量法相比,NeRF根据少量的 2D 图像即可对 3D 场景的几何形状和外观进行建模。
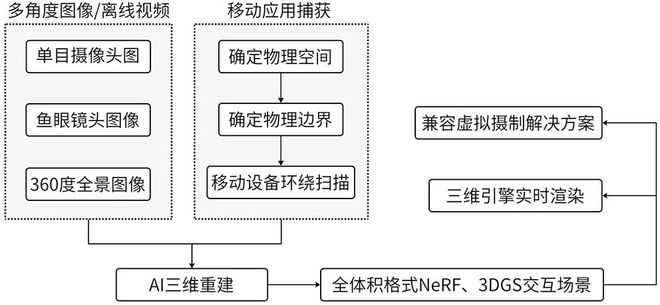
如Volinga Exporter组件克服了无法实时渲染NeRF和缺乏与实时渲染引擎的集成所带来的障碍,为虚拟摄制中的环境拍摄(使用Volinga Creator)和渲染(使用Volinga Renderer)提供了一个快速流程。此外,Volinga的工作流也与当前广泛使用的虚拟摄制解决方案兼容,如Disguise RenderStream和Pixotope。Luma AI支持仅使用具有深度摄像头的iPhone手机实时创建全体积格式Luma AI NeRF(.luma)和基于高斯溅射的交互式场景(.ply)。使用手机缓慢围绕物体或场景进行拍摄,以自动生成用于构建三维场景的一系列连续图片,发送至Luma AI 在本地进行渲染,无需对网格格式、几何、材质进行任何调整,即可嵌入到虚拟摄制、VR制作等后续工作流中。
基于NeRF的三维重建技术能够极大减少数字资产制作过程中所需的劳动成本,建模、纹理、优化、照明等琐碎的工作环节都将变得智能且高效。NeRF模型基于机器学习的体渲染技术,通过使用大量图像数据训练深度神经网络,能够从任意视角重建出高度线D场景,不需要预先定义的视图或摄影机设置,视角依赖性小。然而,体渲染技术目前缺乏成熟的建模、渲染、优化工具等生态系统,阻碍其在下游任务中的应用。此外,由于NeRF是在神经网络中进行隐式重建,在涉及到表面、纹理等显式结构时难以实现物理仿真,其计算量巨大的渲染过程也限制了其在对动态环境和实时渲染有较高要求的虚拟摄制中的应用。同时,NeRF在真实度还原上能多大程度满足电影制作需求,仍需在实践中检验。
AI直接生成3D模型技术正逐渐成熟,可从二维图像、视频或文本描述中直接生成三维模型。如DALL·E 3D基于扩展的神经网络架构,可以接受复杂的文本输入,输出相应的3D模型;NVIDIA Omniverse支持从图像到3D模型的智能生成和调整;Luma Labs推出的Genie 1.0提供对生成的模型更改材质,包括金属、反射、粗糙度等选项,或重新拓扑,也可根据需要导出更高分辨率的模型。
AI能大幅加快3D模型生成过程,减少了传统建模手动操作所需时间。然而,创作者对生成过程的控制相较图片生成更为有限,特定细节的手动调整比较困难。目前,AI生成的3D模型普遍难以达到可直接使用的质量,其主要原因之一是生成的模型贴图往往自带明暗信息,无法生成真实的漫反射贴图和成套的物理基础渲染(PBR)贴图,限制了其在场景中的光照,未来结合AI重定向光照技术,除了辅助AI生成三维模型的真实性效果外,在虚拟摄制的画面后期调整操作性上也存在更多可能性。
此外,结合特定数据集的训练,AI可基于简单的文本或图像提示生成三维纹理和材质贴图,并附带法线、置换、模糊反射、环境光遮蔽等通道贴图,大大提高其在三维制作流程中的可用性。如Adobe Substance Alchemist可从单个图片生成复杂材质,或进行素材混合和风格转换。Poly提供了不同的渲染选项和照明选项,能够在生成时调整纹理属性、地图可见性、光照效九游娱乐平台果。AI基于文生图技术,结合三维材质图像的需求和特点进行特定的功能整合,为数字艺术创作提供了实用的生产工具。
在电影虚拟摄制中,AI生成的3D纹理与材质已得到多样化应用。如创建虚拟场景时,AI可根据输入的图像或视频信息,自动生成与真实环境模型高度匹配的纹理和材质,并针对同一环境快速输出大量背景材质、地板材质、主体材质的不同搭配,为虚拟环境设计方案提供多样化选择。虽然目前由AI创建的材质质量效果和Substance Designer这类程序化贴图制作软件相比仍有一段距离,但其为快速构建真实可信、自定义性高的虚拟环境提供了一种辅助创意高效执行的解决方案。
无标记点动作捕捉(Markerless Motion Capture, MMC)是一种不依赖传统动作捕捉系统中的物理标记点、服装或设备的技术。基于图像识别,AI能实时进行无标记点动作捕捉和离线视频向三维动画的转换,分析人体运动并创建逼线D模型和三维动作数据(图11)。Rokoko Studio、DeepMotion、Move AI等工具提供了一种极其自然和直观的方式来开发、训练、建模和制作3D 角色动画,无需特殊硬件、记录设备或大型软件应用程序,能够实现物理过滤、运动平滑、脚部锁定、面部捕捉、手部捕捉、多人捕捉等功能。其基于图像的动作识别技术,也为控制虚拟元素提供了手势、动作等新的交互方式。

无需穿戴任何传感器或设备,通过图像分析实现对人体姿态和运动的精确捕捉,如捕捉舞者或演员的表演。针对不同角色模型进行骨骼重定向后,可实时映射到如MetaHuman等其他绑定骨骼结构的虚拟角色和数字人中,驱动角色运动(图12)。通过组合多个摄像头,能够很容易地搭建实现多人虚拟互动、虚实互动等以往难以实现的互动效果。

AI无标记点动作捕捉允许创作者通过消费级摄像头捕捉高质量的动作数据,不受特定场地或设备限制,无需特殊的红外反光点或传感器,仅依靠在线录制或离线视频画面,大大降低了传统虚拟摄制流程中由动作捕捉生成角色动画的成本和技术门槛,但其基于AI算法的纯视觉无标记点动作捕捉系统,在动作细节上仍然具有精细度不足的问题,脚部和地面的关系处理、演员站立不动时的数据稳定程度仍然无法媲美专业穿戴式设备。光照条件、拍摄角度和背景复杂度等因素都可能影响视频分析的准确性,从而限制其使用环境的灵活性。在电影制作项目中,往往需要处理时间较长、人数较多、与场景物体交互复杂的任务动作,AI的处理能力和处理质量仍是需要考量的因素。
AIGC在虚拟摄制中可快速生成3D模型、纹理、动画等,并且高效生成三维虚拟场景,深刻地影响了电影虚拟摄制各阶段的工作内容。 智能化的内容生成和交互避免了创作者重复劳动,而且显著降低了制作成本,减轻了电影虚拟摄制中后期前置的工作量。
同时,尽管AI技术在生成模型、纹理和场景等方面存在一定的质量局限性,但这些限制在虚拟摄制和现场拍摄中通常是可接受的。这种互补匹配的科技融合创新模式,能够有效地将AIGC技术与电影虚拟摄制深度融合起来,为该技术的进一步推广提供有力支撑。
展望未来,随着AI技术和虚拟摄制的不断发展进步,AIGC在电影虚拟摄制中的应用将更加广泛和深入,AI将为整个电影制作行业带来更多的可能,促进电影产业的稳步发展与优化升级。
[2] 赵建军,陈军,肖翱.基于LED背景墙的电影虚拟化制作实践探索与未来展望[J].现代电影技术,2021(12):6⁃12.
[6] 中国电影科学技术研究所等.中国电影数字制作规范[M].中国电影出版社,2023.
[19] 米春林,王梓锋.基于LED背景墙虚拟拍摄中的光线匹配技术研究[J].现代电影技术,2022(09):26⁃32.
[21] 卢柏宏,陈军,赵建军.基于LED背景墙的电影虚拟化制作中的照明技术研究[J].现代电影技术,2022(07):10⁃19.
【项目信息】北京电影学院人才队伍建设资助计划——领军人才项目“基于LED背景墙的电影虚拟化制作”(3040025002);2023年度国家社会科学基金艺术学重大项目“创建人类文明新形态视野下的国家战略性影像创作与传播研究”(23ZD06)。
新闻资讯
-
2025-04-02 22:32:48
陈词滥调下的光影呓语——《异星战境
-
2025-04-02 22:32:37
《GTA6》被爆再次跳票或延期至2026年发售
-
2025-04-02 22:32:24
OPPO Find X8 Ultra渲染图曝光:外观设计基本保持不变
-
2025-04-01 22:25:25
苹果和Meta都在强推的沉浸式电影《阿凡达》导演卡梅隆也加入了
-
2025-04-01 22:25:15
比亚迪唐DM-i智驾版上市:1798万~2198万元
-
2025-04-01 22:25:01
新版《超人》制作全揭秘!15大看点详解+幕后故事曝光!

 QQ客服
QQ客服 